Using Twitter X Scraper with Python
Using Twitter X Scraper with Python
The Twitter X Scraper is a powerful tool for extracting data from Twitter (now X.com). This guide walks you through setting up and using it with Python.
Prerequisites
Before you start, ensure you have:
- Python (version 3.7 or higher).
- An Apify account with an API key.
- Basic Python programming knowledge.
Installation
Install the required Python library:
pip install apify-client
Setting Up the Scraper
-
Obtain an API Key
Log in to your Apify account and generate an API key from the Setting -> API & Integrations section.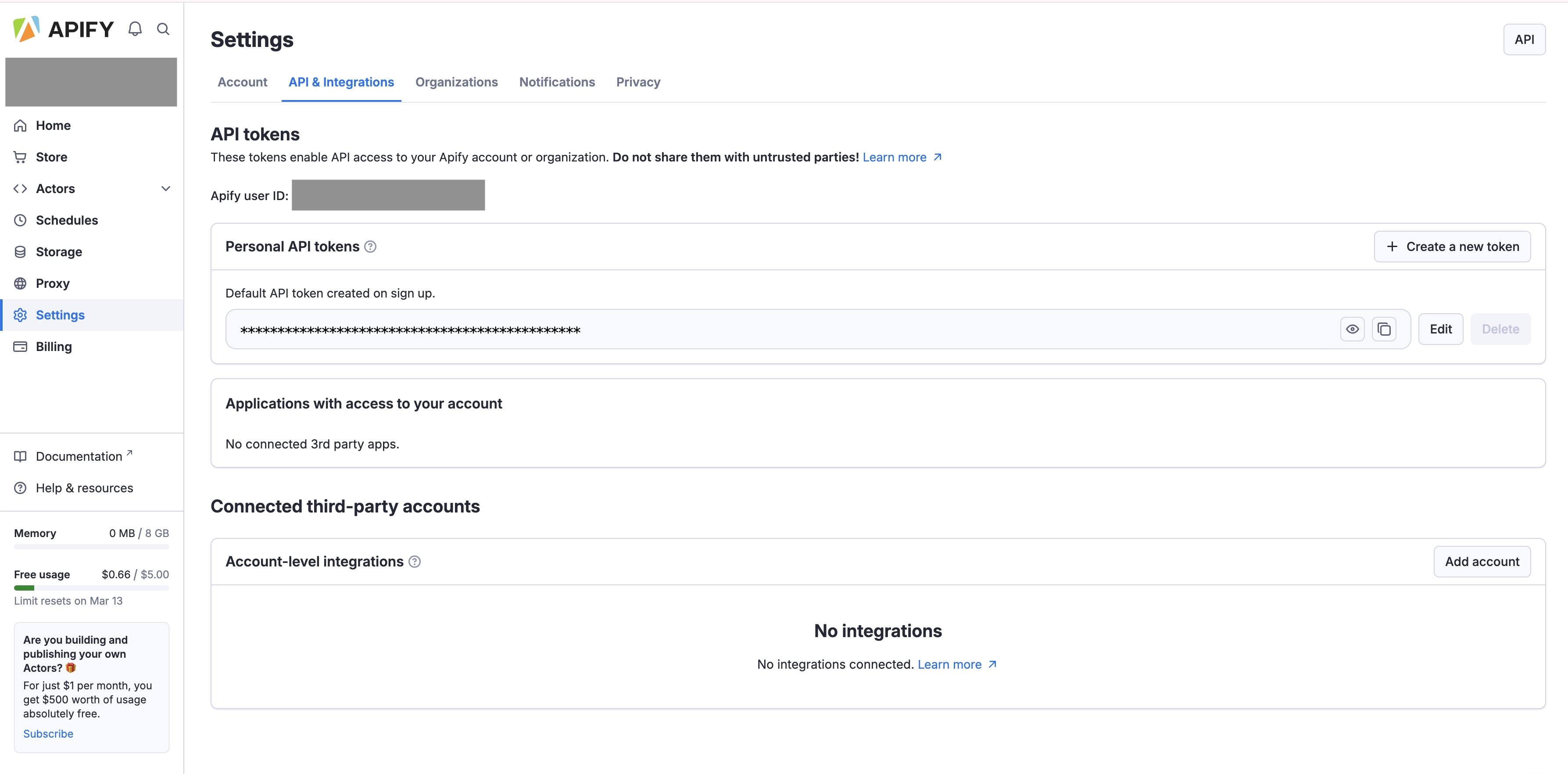
-
Initialize the Apify Client
Use the API key to authenticate in Python:from apify_client import ApifyClient # Initialize the Apify client client = ApifyClient("your_api_key_here")
Running the Scraper
To scrape data, you need to provide input parameters. For the xtdata/twitter-x-scraper Actor, the main input field is searchTerms.
Here is a complete, robust example that includes error handling and pagination limits:
from apify_client import ApifyClient
# Initialize the Apify client
client = ApifyClient("YOUR_API_TOKEN")
# Define the actor ID for Twitter X Scraper
actor_id = "xtdata/twitter-x-scraper"
# Set up advanced input parameters
input_data = {
"searchTerms": ["#Python", "#WebScraping"],
"maxTweets": 100,
"sort": "Top", # Can be "Latest" or "Top"
"tweetLanguage": "en",
"onlyVerifiedUsers": False, # Set to True to filter spam
"onlyImage": False
}
print("Starting the Twitter Scraper...")
try:
# Run the actor and wait for it to finish
run = client.actor(actor_id).call(run_input=input_data)
# Fetch the results from the actor's default dataset
dataset_id = run.get("defaultDatasetId")
if dataset_id:
print(f"Scraping successful! Dataset ID: {dataset_id}")
results = client.dataset(dataset_id).list_items().items
print(f"Extracted {len(results)} tweets.")
# Print the text of the first 3 tweets
for i, item in enumerate(results[:3]):
print(f"\n--- Tweet {i+1} ---")
print(item.get("text", "No text found"))
else:
print("Run finished, but no dataset was generated.")
except Exception as e:
print(f"An error occurred during scraping: {e}")
Customization Options
You can modify the input_data dictionary to highly customize the scraper’s behavior:
- Search by User: Add
"from:username"to thesearchTermslist. - Filter by Date: Add
"since:2024-01-01 until:2024-02-01"to your search terms. - Specific Media: Toggle
onlyImage,onlyVideo, oronlyQuotetoTrue.
Handling and Exporting Results
The scraper outputs raw JSON data which is perfect for APIs, but for data analysis, you likely want a tabular format. You can easily process the results using the pandas library:
import pandas as pd
# Assuming 'results' contains the list of dictionaries from the dataset
if results:
# Convert results to a pandas DataFrame
df = pd.DataFrame(results)
# Select only the most relevant columns to keep the file clean
columns_to_keep = ["id", "text", "createdAt", "retweetCount", "likeCount", "viewCount", "url"]
df = df[[col for col in columns_to_keep if col in df.columns]]
# Save to a CSV file
df.to_csv("twitter_data.csv", index=False)
print("Data successfully saved to twitter_data.csv")
Best Practices
- Respect Terms of Service: Comply with Twitter’s guidelines.
- Rate Limiting: Avoid excessive requests.
- Data Privacy: Handle user data responsibly.
Using this guide, you can effectively scrape and process data from Twitter using the Twitter X Scraper and Python. Happy coding!
Related Guides
Explore more ways to extract data from X.com (Twitter):
- 📖 Tutorial: Scrape Twitter Data with Tweet X.com Scraper — Step-by-step guide with advanced search operators
- 🖱️ Scraping X.com Without Writing Code (2025) — No-code guide for non-developers
Looking for data extraction tools?
Check out our comprehensive collection of no-code scrapers and APIs for TikTok, X.com, and more.